一、转换说明
本篇主要讲述如何把我们写好的机器代码文本转为可烧录使用的二进制文件。因为我们之前写的机器代码实际上不算是真正的`0`和`1`,直接把我们写的代码给机器看,机器是看不懂的。因为我们在文本文件里写的0和1实际上只是经过系统编码后显示的字符,和a、b、c这些字符一样没有区别,芯片是没办法直接识别成真的`0`和`1`的。 所以我们必须要把文本转为二进制的方式,下面我们就通过写一个python脚本的方式来实现把文本转为二进制并生成一个bin文件。然后我们就可以直接使用烧录工具读取并烧录了。二、大小端说明
编写转化脚本之前我们先要了解一下数据在机器内部的两种存储方式,即大端模式和小端模式。我们可以先看一下《Cortex-M3权威指南》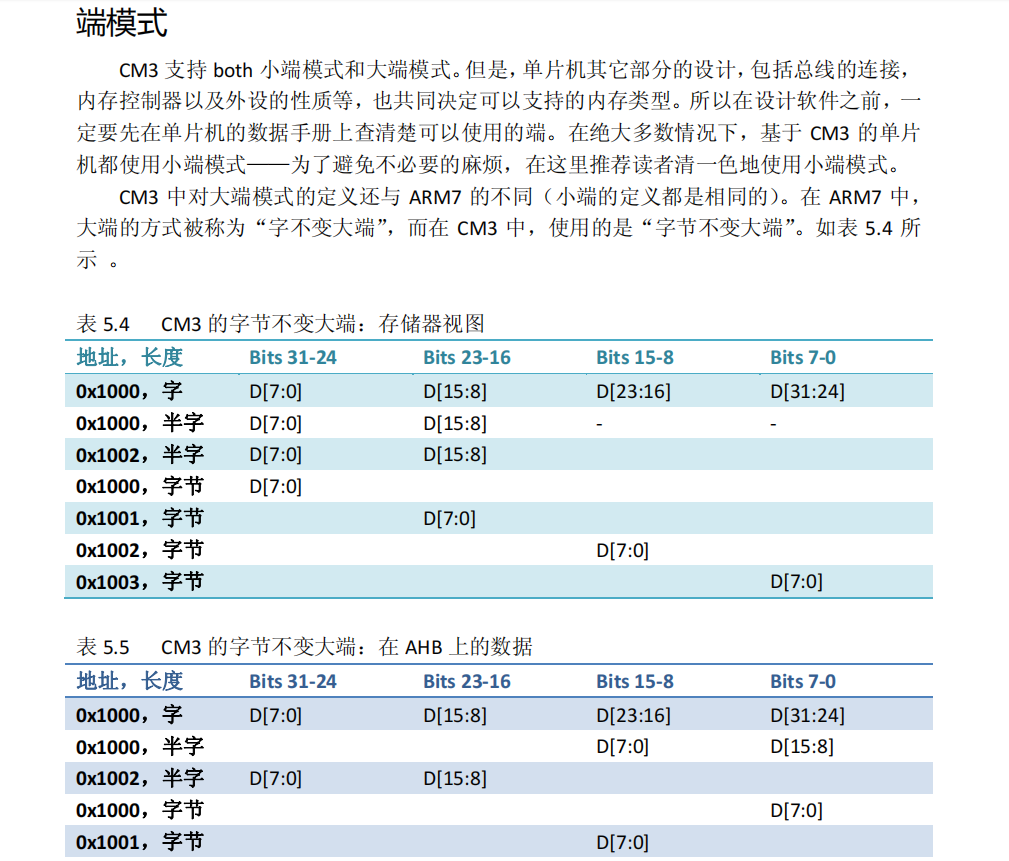
可以看到,CM3是支持大端和小端两种方式的,但是按文档里的一般推荐使用的小端模式,本教程也将使用小端模式。
存储方式其实就是我们编写的二进制数据和其他系统二进制数据在内核里是以什么顺序存储的,比如系统FLASH地址是从0x0800 0000开始,我们要向里面写入一个4字节的数据
0x12345678,那究竟是按0x12、0x34、0x56、0x78这样的方式写入0x0800 0000-0x0800 0004;还是按0x78、0x56、0x34、0x12这样从大到小的方式写入0x0800 0000-0x0800 0004。这就是大小端的区别。
1、大端模式
大端模式就是以和存储位置排序相反的方式写入数据的,还是按上面的例子,我们有一个四字节的数据0x12345678,我们就按字节存储。那0x12在这数据里是高位字节,在大端模式下,它会被写入地址的低位0x0800 0000,然后0x34在这数据里是次高位,而存入系统里时是在0x0800 0002这个次低位,同样的0x56会存在0x0800 0003处,而数据里的最低位0x78会保存在存储空间的最高位0x0800 0004。说白了就是在大端字节方式中,数据的高位字节存储在内存的低地址处,而低位字节存储在内存的高地址处。
以上是以大端字节的方式说明,本次的二进制转化我们不使用这种方式。

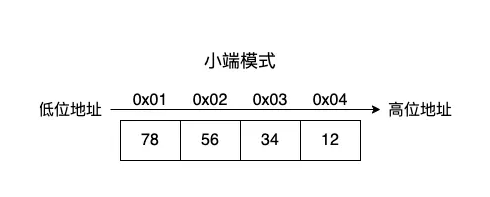
2、小端模式
小端模式正好和大端模式相反,小端模式是数据存储顺序和内存地址顺序一致,数据的高位会存储在存储空间的高位,而低位存在空间的低位。还是上面的例子,以小端字节的方式写入的话,0x78、 0x56、 0x34 、0x12会分别存储在内存空间的0x0800 0000、0x0800 0001、0x0800 0002、0x0800 0003。
本次我们使用小端模式来转化我们的机器代码文本。
3、数据宽度
其实了解了大小端模式之后,我们还要了解一个就是数据宽度。数据宽度就是我们“一次性”写入的数据长度,或者说是内核系统是以什么样的长度来读取我们的数据。而我们说的大端和小端其实就是在我们的数据宽度的基础之上去排序的。比如我们有一个32位的地址数据0x12345678要存储到内存空间里,并且是以小端字节进行存储,假设和上面的例子一样内存空间从0x0800 0003开始,那存储的位置就是 0x12、 0x34、 0x56 、0x78会分别存储在内存的0x0800 0003、0x0800 0002、0x0800 0001、0x0800 0000。这个和我们上面的例子结果是一样的。但是如果我们要写入的是一个Thumb-2的指令0x12345678,尽管这个指令有32位,但是由于我们内核加载Thumb-2指令的时候都是按照16位的数据宽度来读取的,所以我们写入内存空间时也要按16位“一次”的方式写入。那这时候在内存空间的布局就变成了:0x34 、0x12存储在0x0800 0000、0x0800 0001;0x78、 0x56存储在0x0800 0002、0x0800 0003。目前Cortex-M3内核里,地址数据的读取数据宽度都是32位,而指令的读取数据宽度是16位。所以我们写转化脚本的时候必须要区分我们写的机器代码是数据还是指令,这样我们的脚本就能决定是按16位数据宽度还是按32位数据宽度写入。
三、脚本编写
在编写转换脚本之前,我们先再看一下我们的代码:
最终的代码小本本:
1 | # 写在FLASH 0x0800 0000处的第一行代码---指定栈顶 |
从我们的代码文本里我们发现,还漏了一个东西,结合我们刚刚说的数据宽度,我们发现这些机器代码好像没有标识能区分哪些是需要以32位宽度写入的,哪些是需要以16位宽度写入的。所以我们干脆给他加个标识t和T吧,使用大写T开头,小写t结尾把16位数据宽度的机器代码给包围起来(t的意思可以指是thumb😀)。
比如有机器代码:
1111 0010 1100 0100 0000 0000 0000 0001
1111 0010 0100 0010 0000 0001 0000 0000
T
1110 0111 1111 1110
1111 0000 0100 0001 0000 0001 0001 0000
t
0010 0000 0000 0000 0101 0000 0000 0000
这时候,我们把第1行、第2行和最后一行都按32位数据宽度来进行小端字节的方式写入硬件,而第4行、第5行以16位数据宽度的方式小端写入。
开始写脚本
1、我们先定义两个参数就是源代码文本文件和目标二进制文件,input_file_path、output_file_path。
2、使用with open(input_file_path, 'r', encoding='utf-8') as input_file, open(output_file_path, 'wb') as output_file:加载代码文本文件和输出的二进制文件。
3、定义一个binary_string用于接收一个数据宽度的二进制位,再定义一个dataWidth用来标识当前是16还是32位的数据宽度,再使用一个变量notes来标识当前读取的是注释还是代码。
4、使用for char in input_file.read():一个字符一个字符的读取文件内容。然后在循环里判断读取的字符是属于‘#’符号的话就代表开始读取到注释内容,就把变量notes置为True,并且跳过当前迭代继续下一个字符。如果读到换行符\n就代表注释结束(目前#符号的注释只支持一行),然后把变量notes置为False表示注释结束。
5、如果在读取的字符不是处于注释状态并且字符属于0或1的话,就把字符放入binary_string,然后判断binary_string里面的字符数量,如果长度满足了当前数据宽度dataWidth的长度,就开始将binary_string转为小端序的字节序列,并写入二进制文件output_file_path。写完后重置binary_string为空。
6、判断读取到的字符是否属于T或t,如果是T,就把变量dataWidth设置为16,如果是t,则代表thumb指令结束,把数据宽度dataWidth设置为32。
上面就是编写代码的思路,我们编写好后如下:
python脚本:
1 | import argparse |
四、脚本使用
写好脚本后可以命名为toBin.py,脚本的使用很简单,安装好python环境之后,直接使用命令行输入python toBin.py即可。默认读取的源代码文件是input.q(.q后缀是我乱取的),默认输出的二进制文件是output.bin。也可以通过参数来配置输入文件和输出文件,比如:
python toBin.py -i 机器代码源码.txt -o 输出的二进制文件.bin
我们执行完后就可以用烧录软件烧录到我们的stm32设备上啦。
注:这里有个地方需要注意,我们转译后的bin文件是只保存二进制信息,是没有代码和数据的位置信息的。这意味直接烧录的话,我们所有的数据代码都是连续的烧录到机器上,比如我从0x0800 0000的位置开始烧录,那会把我们这份二进制数据从0x0800 0000开始到我们bin文件的长度结束,如果我们的bin长度是0x30,那烧录保存进机器的范围就是0x0800 0000-0x0800 0030。这就要求我们在写代码的时候计算好每块代码区域函数这些东西的长度和其实地址,比如我们的复位中断函数的地址是要我们手动写进中断向量表的,但是如果我们的复位中断函数的第一条指令不是我们写在向量表的那个地址,那机器就找不到中断函数的地址了。
其实我们写的这份机器代码,如果直接烧录,那地址是对不上的,因为我们在中断向量表里把复位中断函数的地址设置为了
0x0800 0131,但如果烧录进系统,我们的复位中断函数的地址是不在0x0800 0131这个位置的,所以我们如果要想在这里可以直接烧录就运行的话,就得改一下复位中断向量的地址,按我们这个代码来计算,改成0x0800 0011=0000 1000 0000 0000 0000 0000 0001 0000就可以正常启动运行了。还有后面的两个中断函数的地址,也是需要改一下的。而之前写的时候为啥不直接改呢,就是因为我们后续的教程还会手把手教大家怎么把二进制文件分段写入STM32的存储器。



